
We recently moved several of our projects to the new Google Cloud Build for building container images and pushing them to the repository. It’s a pretty simple system (not a full CI) but it does the job well, and I liked having the “build” part separate from the “run tests” part of the toolchain. That said, I feel like this is among the many tools that leave me writing bash scripts in YAML.
Disable Rails bootsnap in Production
We recently upgraded many of our services to Rails 5.2 which installs bootsnap to make start-up faster. However, bootsnap depends on caching data to the local file system and our production containers run with read-only file systems for security. So I decided to remove bootsnap in production:
# Gemfile #... group :development, :test do gem 'bootsnap', '~>; 1.3' end #... # config/boot.rb #... require "bundler/setup" # Set up gems listed in the Gemfile. begin require "bootsnap/setup" # Speed up boot time by caching expensive operations. rescue LoadError # bootsnap is an optional dependency, so if we don't have it it's fine # Do not load in production because file system (where cache would be written) is read-only nil endContinue reading “Disable Rails bootsnap in Production”
How we reduced EC2 costs 98% with spot instances
Last year we changed our EC2 system from long-running instances to on-demand, spot request instances. This reduced our EC2 bill by 98%. It also ensured that every instance was built with the latest image and security patches and ran only as long as needed.

Continue reading “How we reduced EC2 costs 98% with spot instances”
Autoscaling Resque with Kubernetes
We run lots of background jobs and background workers. Some of these are pretty consistent load and some vary greatly. In particular we have a background process that can consume 30GB or more of memory and run for over a day. For smaller workloads it could complete in 15 minutes (consuming a lot less memory). At other times this queue can be empty for days.
Traditionally Resque is run with one or more workers monitoring a queue and picking up jobs as they show up (and as the worker is available). To support jobs that could scale to 30GB that meant allocating 30GB per worker in our cluster. We didn’t want to allocate lots of VMs to run workers that might be idle much of the time. In fact we didn’t really want to allocate any VMs to run any workers when there were no jobs in the queue. So we came up with a solution that uses Kubernetes Jobs to run Resque jobs and scale from zero.
We’ve open sourced our resque-kubernetes gem to do this.
PostgreSQL Monitoring and Performance Tuning: Phase 2
This is a follow up on the post PostgreSQL Monitoring and Performance Tuning.
In order to get the most out of our servers I was tracking PostgreSQL’s use of memory and temporary disk space. It seemed that we were pushing the attached disks beyond their capabilities, so I set up a chart to track disk utilization. While I was able to increase work_mem and not see any deleterious effects, if we went too high we would run out of memory, so I set up a chart of percent of memory used.
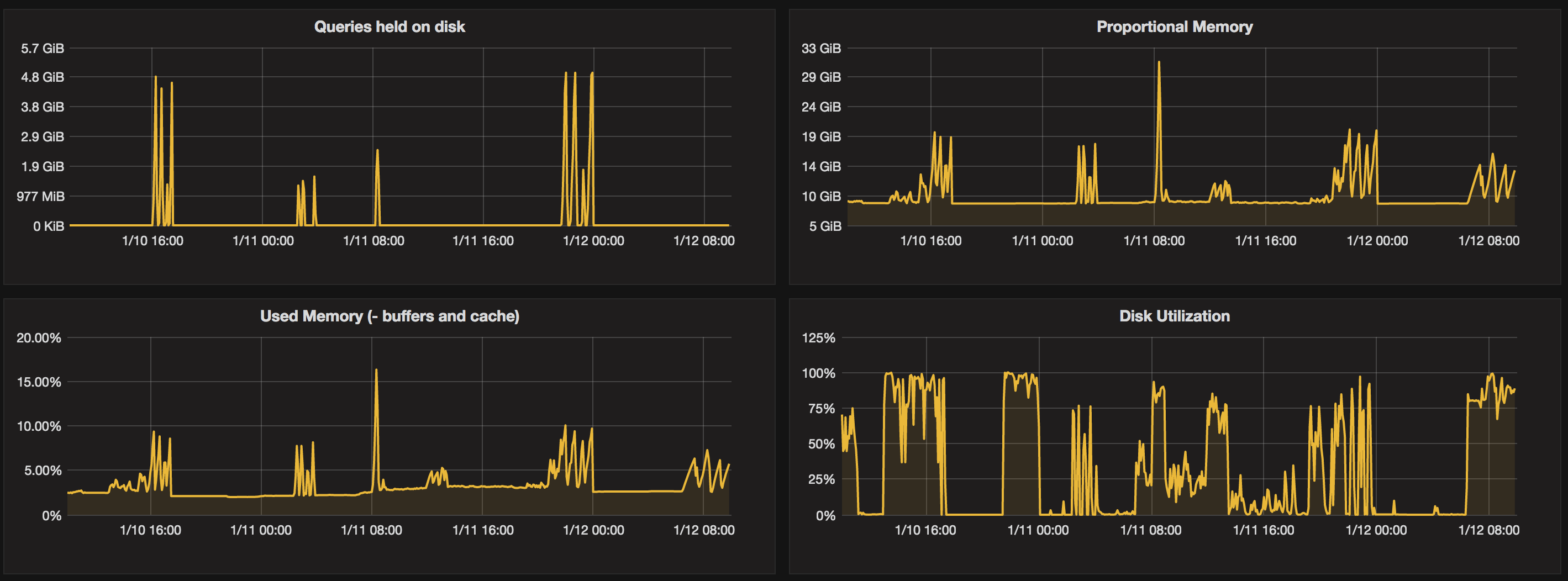
By monitoring these while I increased the work_mem, I found the point at which queries held on disk dropped to very little and disk utilization dropped from being pinned at 100%.
Continue reading “PostgreSQL Monitoring and Performance Tuning: Phase 2”
Moving to Google Cloud Platform, Docker, and Kubernetes
Over the past six months we moved all of our infrastructure from virtual machines and bare metal to Google Cloud Platform. We moved much of our systems to Docker and Kubernetes on Google Container Engine (GKE). Our databases we migrated from bare metal to virtual machines in Google Compute Engine (GCE). The entire effort took about 6 weeks of work and 3 months of stabilization. In the end we have mostly better performance (databases are a bit slower), much better scaling options, lower costs, but less stability (we’re working on it; plus resiliency).
I’ve gathered some notes and am doing a presentation on this in the coming week. I’d like to expand on these thoughts some more and will link to future related posts as I complete them. Below are some of the more salient points of the adventure.
Continue reading “Moving to Google Cloud Platform, Docker, and Kubernetes”
PostgreSQL Monitoring and Performance Tuning
As our PostgreSQL database needs grow, I needed to adjust how it used memory to make the most use of what we are paying for. Tuning Your PostgreSQL Server was really helpful in understanding the parameters to adjust, what they affect, and their relative importance. shared_buffers, work_mem, and effective_cache_size are the parameters that I was mostly looking at to get memory use right.

In order to get a good picture and know if my changes were effective I needed to monitor how we were using memory. I set up our servers to record metrics to Graphite and configured a Grafana dashboard to show usage over time.
Continue reading “PostgreSQL Monitoring and Performance Tuning”
CloudEndure: a review
We recently migrated our bare metal databases to Google Cloud Platform. To do that, our Google rep recommended a tool called CloudEndure. I mentioned this to some peers and figured it would be helpful to share a review of the product more broadly.
In short: It’s pretty amazing and once it works it works wonderfully.
CloudEndure can replicate from bare metal or cloud to cloud for migrations or DR. They do a block level migration of the base drive. For moving data to the cloud that meant that once the data was there, at any time I could spin up a “replica” which would begin running as a rebooted server on the disk at the point in time that the last update was made. This made testing and completing a migration of two database servers many hours less work than it would have been to set up slaves.
Their support is very responsive and very helpful as well.
We didn’t have to pay for this service. Google provides it for “free” to get you into their cloud. I still had to pay for the resources used by the replicator in GCP, of course. I learned from another company that outside Google their cost is something like $115/instance/month with a minimum commitment of 10 instances. That’s pretty steep for ongoing disaster recovery.
There were some things I think they could improve:
- The sales pipeline was silly long. Like they felt they needed to keep me in the pipeline. I talked to two different sales people over the course of a week before they would give me access to the tool to start using it. I had already decided to “buy” when I contacted them.
- It took four days to get the initial 7TB of data migrated. They stated that was due to the limits of our outbound pipeline at our datacenter which may be true; I’ve never measured it.
- When we were writing at more than about 20MB/s the replicator lagged behind. Again, they said that they were limited by outbound bandwidth. Their UI wasn’t always clear what was going on, but their support was responsive.
- There were several quotas we had to increase in our GCP project to allow this to work. Fortunately, CloudEndure was responsive and let me know what the issue was the first time and Google increases quotas within about a minute of the request.
- Spinning up a replica can take a couple hours (it was 40 minutes in my first test and 2 hours in my final move.). I am sure it’s just because of all the data being moved around, but I was hoping for something faster. [As a note, when I later spun up new instances from snapshots of the migrated system in GCP it took about 20 minutes.]
- When I stopped replication it removed the agent from the source servers and cleaned up all the resources in GCP, but left the agent running on the replicas (where it had been migrated). I had to contact them to uninstall that manually.
A Man Hears What He Wants to Hear
“Still, a man hears what he wants to hear
And disregards the rest.” — Paul Simon, The Boxer
In the world of “statistics” (which is to say the statement of data; as opposed to the mathematics) there appears a strong affiliation with complex statement that define an inconsequential fact. While not a baseball fan I see this often in popular culture in that sport.
Paraphrasing, “It’s the first time that a third-baseman has hit two home runs in the last four innings of a play-off game!” Or something like that.
Statements like this mean nothing. With increased specificity we feel we have more knowledge when in fact we have less.
It’s not just baseball; it’s business. This same problem underlies many financial and human-welfare decisions. The problem is not thinking of the context in which the “statistics” are stated. The growing p-value concern is evidence of a larger issue: taking statistical (i.e. numerical) results of an analysis and applying them outside the context.
This happens in A/B testing all the time. Which is how some companies build their product and make decisions about revenue and spending.
There is certainly selection bias and cognitive bias at hand in human nature. “Question everything” is one response, but not, strictly, reasonable. We need to accept conclusions from others if we are to work collaboratively. And stand on the shoulders of giants.
Peer review is how the scientific community has addressed this for years. Writers have always had editors and now customer peer reviews. We have this in the software world through code review. GitHub has done a great job of making pull requests the best code review tool I’ve ever used. Still, selection bias (“I’m not qualified to review that”) and cognitive bias (“looks good to me”) still exist.
This is your call to reach out to those you think might disagree with you and have them review your work. My favorite way to ensure that I have a great solution or have made the right conclusion is to convince someone who is skeptical. (Unless power dynamic or group think come into play.) What’s yours?
How do you fsck or change /etc/fstab when root is read-only?
I’m upgrading a server again and we replaced the RAID array with SSDs (it’s a 10x IOPS improvement; so worth it). But booting the system it fails to start because the old UUID listed in /etc/fstab is no longer available.
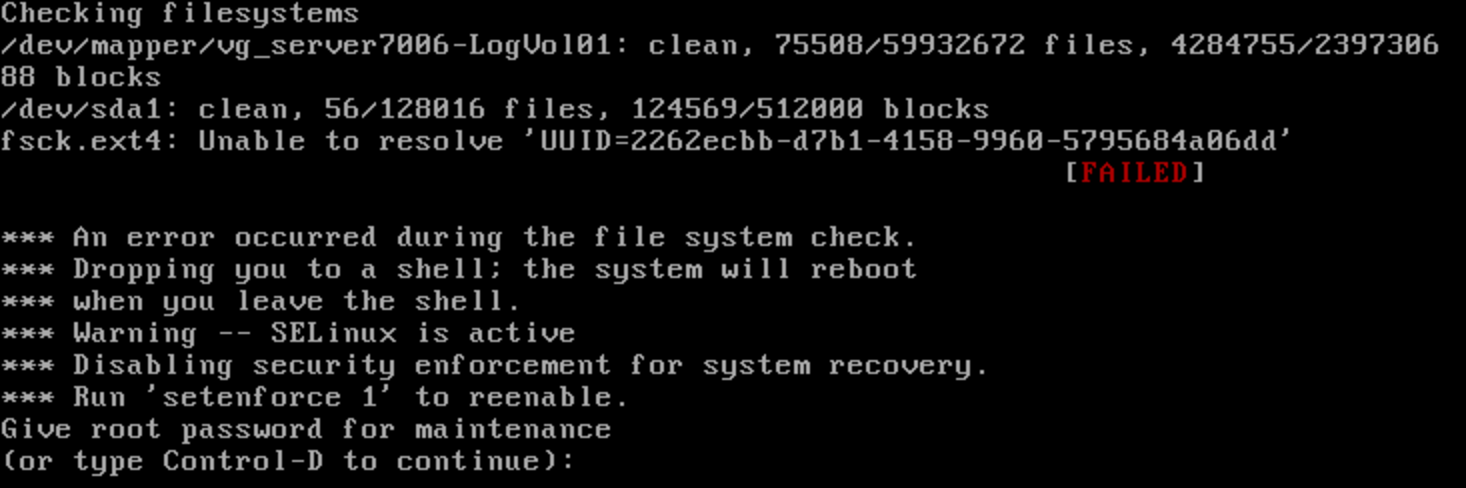
That “Unable to resolve” message caused the filesystem check to fail. Linux drops into a shell with the root volume loaded but in read-only mode.
To fix this I needed to change /etc/fstab to remove the offending entry. But I couldn’t write to the file system.
The obvious solution (with help from our hosting partner) is to remount the root partition as read-write:
mount -o remount,rw /
Now, I can edit /etc/fstab, comment out the offending line, exit and the system will reboot into a running server.
