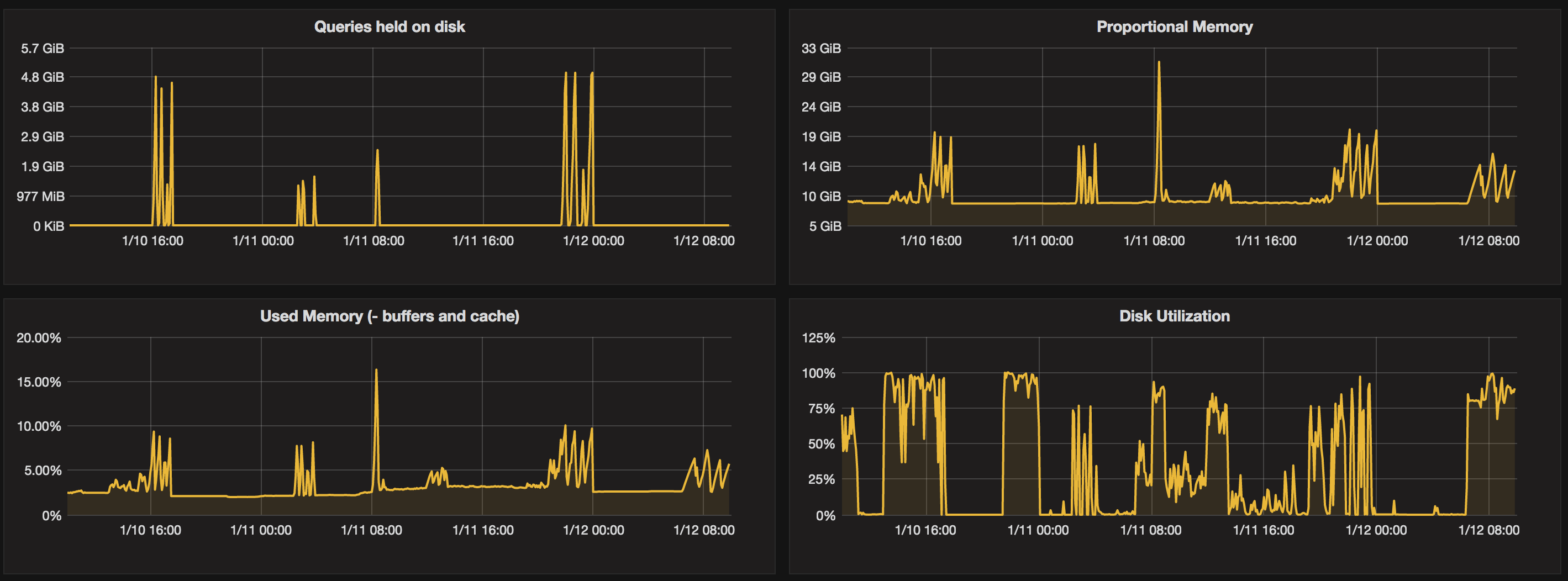
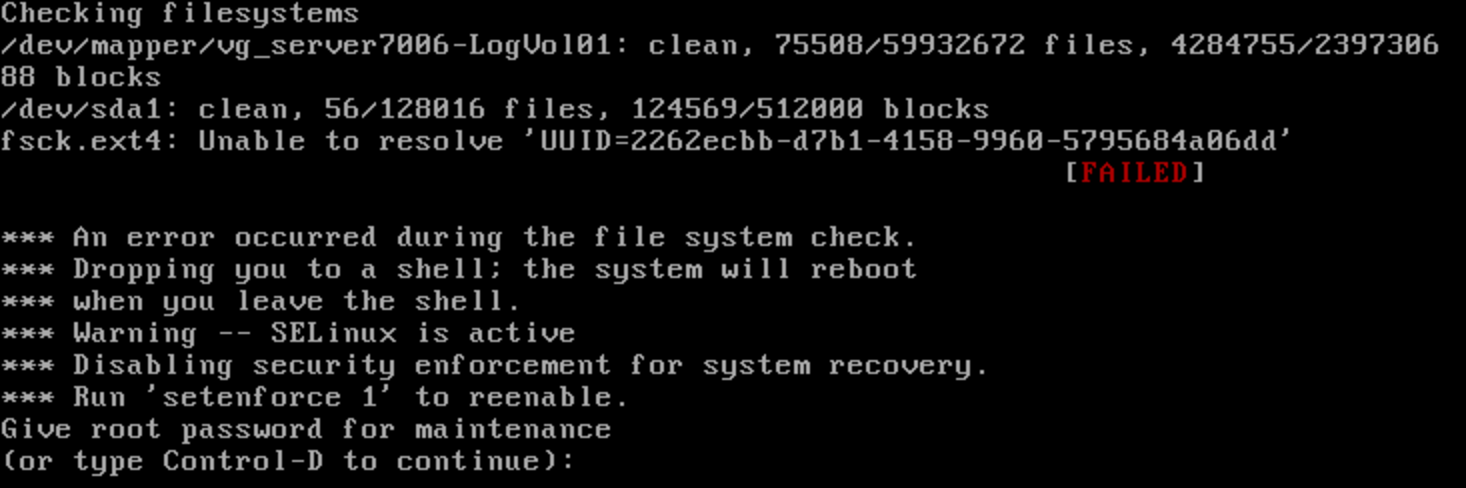
“Still, a man hears what he wants to hear
And disregards the rest.” — Paul Simon, The Boxer
In the world of “statistics” (which is to say the statement of data; as opposed to the mathematics) there appears a strong affiliation with complex statement that define an inconsequential fact. While not a baseball fan I see this often in popular culture in that sport.
Paraphrasing, “It’s the first time that a third-baseman has hit two home runs in the last four innings of a play-off game!” Or something like that.
Statements like this mean nothing. With increased specificity we feel we have more knowledge when in fact we have less.
It’s not just baseball; it’s business. This same problem underlies many financial and human-welfare decisions. The problem is not thinking of the context in which the “statistics” are stated. The growing p-value concern is evidence of a larger issue: taking statistical (i.e. numerical) results of an analysis and applying them outside the context.
This happens in A/B testing all the time. Which is how some companies build their product and make decisions about revenue and spending.
There is certainly selection bias and cognitive bias at hand in human nature. “Question everything” is one response, but not, strictly, reasonable. We need to accept conclusions from others if we are to work collaboratively. And stand on the shoulders of giants.
Peer review is how the scientific community has addressed this for years. Writers have always had editors and now customer peer reviews. We have this in the software world through code review. GitHub has done a great job of making pull requests the best code review tool I’ve ever used. Still, selection bias (“I’m not qualified to review that”) and cognitive bias (“looks good to me”) still exist.
This is your call to reach out to those you think might disagree with you and have them review your work. My favorite way to ensure that I have a great solution or have made the right conclusion is to convince someone who is skeptical. (Unless power dynamic or group think come into play.) What’s yours?