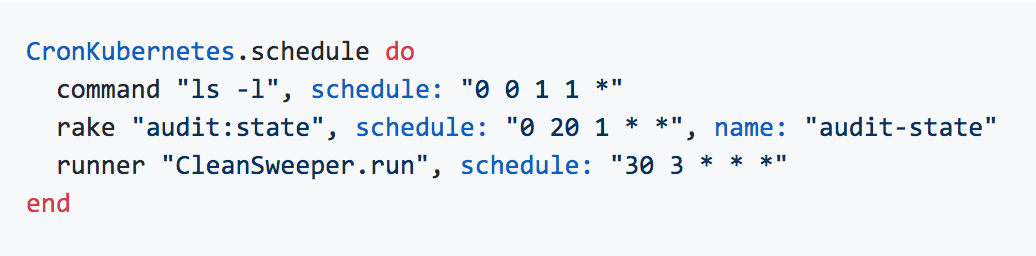
We’ve been running a bit of a baking-off of observability tools for the past few years. Over the last couple months we integrated Google Cloud Monitoring (formerly Stackdriver Metrics) to track custom application metrics. The impetus for this was two-fold:
- Reduced cognitive load: it’s baked into Google Cloud so it’s theoretically one less tool to have (although GCP Console is so vast I think of it as many tools)
- Reduced operational costs
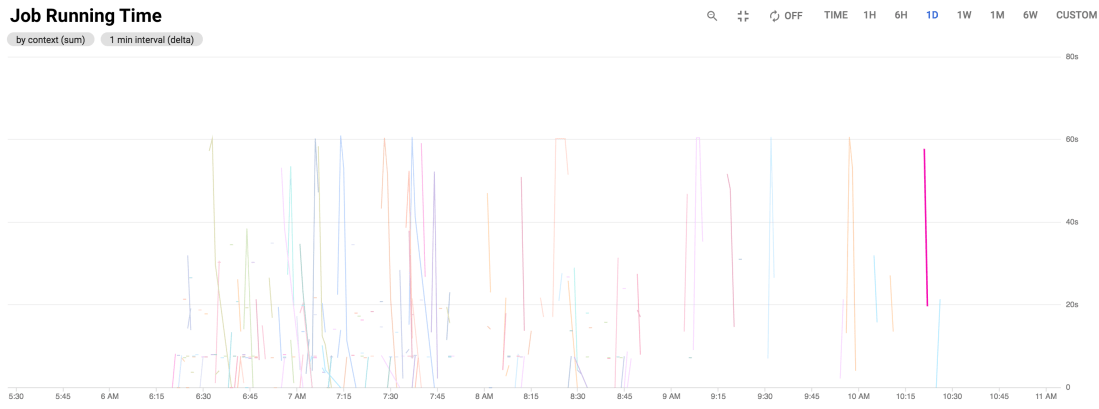
The upshot is that it is inordinately complicated to get working (both the engineering and the visualizations) and I don’t think the investment in effort to implement it is worth any savings in on-going costs. Even though Stackdriver was founded in 2012, the tooling feels really basic (likely because of the long integration time into Google Cloud) compared to competitors. The off-the-shelf reports are very high-level, and the interface is buggy and slow.
Continue reading “Google Cloud Monitor Metrics: a Review”