We run a Rails application as Docker containers in Kubernetes. Our application and services have a fair number of scheduled tasks and before we moved to containers these ran using cron in the VM that the server ran on. When we moved to Docker we first migrated by deploying a container that just ran our cron jobs. We’ve now migrated those to native Kubernetes Cron jobs which vastly improved the resiliency of our system.
Previously we had used the whenever gem which has a simple design. You add a config/schedule.rb file to your application and then use whenever to install the crontab when you deploy. I liked the simplicity of that file and that it made it easy for developers to add new tasks without worrying about how jobs are getting run.
The problem with our old set up was a container (Kubernetes pod) needed to be running all the time to run cron and any restart of the pod would kill running cron jobs and might miss a scheduled job. We had to restart the pod with every code update and with any cluster updates (not to mention Kubernetes scheduler likes to shuffle “low utilized” nodes).
Moving to Kubernetes, I had looked at the native CronJobs. Then I ignored it for at least a year because I already had reached maximum capacity in my head for Kubernetes things. Eventually it was time to make a move — the persistent cron container was causing problems and I didn’t want to spin up another one when launching a new service.
Using CronJobs would resolve the restart issue, allowing each job to run as long as needed, make sure the jobs run, and retry failed jobs. The problem was that was building a Kubernetes manifest for each scheduled task was a lot of work, a lot of duplication of code and effort, and would be a burden for developers to add new scheduled tasks.
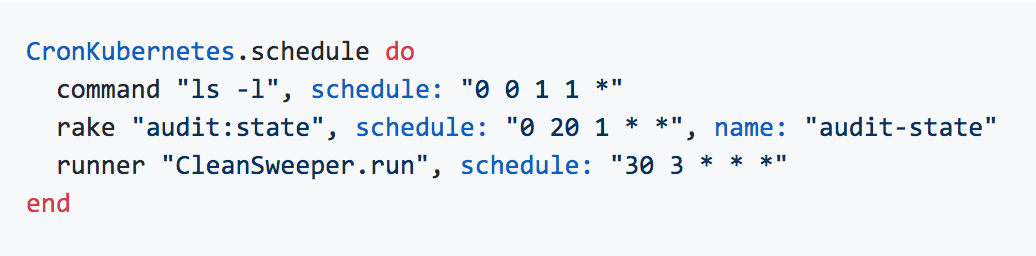
So we released the cron-kubernetes gem. It encapsulates the process of creating Kubernetes Cron Jobs and allows developers to schedule new code and tasks with a simple configuration, much like whenever‘s config/schedule.rb file:
CronKubernetes.schedule do command "rm -r /tmp/*", schedule: "14 0 1 * *", name: "clean-tmp" rake "cache:clear", schedule: "44 17 * * *", name: "clear-cache" runner "TrialsMailer.send_expired", schedule: "37 13 * * *", name: "expired-trial" end
The sample schedule above shows three kinds of tasks. A shell command (command), a Rake task (rake) and running Ruby code in the Rails environment (runner; equivalent to bin/rails runner ...).
There are some assumptions that the gem makes about your environment:
- All your cron jobs will run the same Docker image and have essentially the same manifest
- Your cron jobs are all run within the scope of your Rails application
See the gem README for more details about setting it up and configuring it.
It was a fun 4-day project and allowed me a deep dive into another aspect of Kubernetes, not to mention a lot of testing and debugging of the kubeclient gem that it depends on.
We’ve been running this in production for about 18 months. It’s made our scheduled tasks much more resilient and has simplified the process of deployment. Since release, we’ve posted a couple fixes for some issues. At this point I feel it’s quite stable and, precluding any significant changes to Kubernetes CronJobs or kubeclient I don’t see any issues arising.
Check out the gem and let me know how it works for you.
